
Introduction to Generative AI - Part 1: Foundation (GPU, data center, computing) and model layer
Breaking down the hype behind Generative AI with in-depth analyses and first-principle thinking to understand the landscape, define key themes, and identify opportunities.

Generative AI has been a widely-used jargon across many communities in the past few years, from businesses (both large corporates, startup operators, investors), academia, to policymakers among others. In Y Combinator’s latest cohort (S23), over 60% of the startups are working on AI; Numbers of AI research publications has more than doubled since 2010; McKinsey's recent report estimated that Generative AI will add US$ 2.6 to 4.4 trillion of value to the global economy annually; Across 127 countries included in AI Index analysis, there were 37 bills about AI which were passed into the law in 2022 (compared to only 1 in 2016).
AI is not a new thing - Businesses have been leveraging AI on broad range of use cases over the past decades, and in an incrementally increasing level of sophistication as well. But what is unique about Generative AI? Why does it receive so much hype now? How do we think about it? And what’s the path forward? These are the questions we will try to unpack in this first series of Beyond the Lineup article on Generative AI.

Generative AI vs Traditional AI
To begin with, it is worth recapping what differentiates Generative AI from traditional AI. To put simply, Generative AI’s strength lies in its ability to create new content (text, image, or audio) in addition to analyzing data and identifying patterns.
In contrast, traditional AI works best in a well-defined domain and unchanging rules. If we think about how businesses had been using traditional AI, it all came down to these 3 categories of analytical problems:
Regression: Predicting a numerical value based on a set of input, for example: stock price forecast, sales & inventory forecast, energy consumption forecast, probability of default / credit risk calculation
Classification: Categorizing data points into pre-defined labels, for example: spam / non-spam email, fraud identification in eKYC, medical diagnosis, NLP (natural language processing) use cases
Optimization: Providing suggestion of product, service, or content based on individual preferences and behavior, for example: Google & Meta ads, e-commerce recommendation, Tiktok FYP recommendation
Generative AI unlocks a whole new sets of AI use cases by creating personalized content beyond solving the above problems, which traditional AI is already very good at. Some examples:
Beyond forecasting stock price (regression), Generative AI can provide interactive virtual trading & portfolio management assistant
Beyond conducting medical diagnosis (classification), Generative AI can write a medical report and personalized recommendation for the patient or even go further by doing an interactive AI consultation
Beyond recommending social media content (optimization), Generative AI can create social media visual content tailored to customer’s preference
Beyond recommending e-commerce goods (optimization), Generative AI can become an interactive e-commerce virtual shopping assistant or create new product designs according customer’s preference and create virtual avatar to help customer visualize the new designs.
Where are we in the Generative AI innovation curve and how did we get here?
We believe Generative AI is at the beginning of our take-off phase, but the pace of adoption will be exponentially faster than previous waves of technology. The first launch of ChatGPT in November 2022 (which managed to reach 100Mn MAU within 2 months) was the inflection point that put Generative AI on the public map, though of course, it is important to note that few other early movers had been building (and investing) in this space in prior years too.
A recent AI report by Coatue described it best. Generative AI adoption is still low but its S-curve is much steeper than internet’s or smartphone’s, indicating its seemingly imminent rapid adoption within the next 12 - 24 months. In fact, in one of 20VC’s The Ultimate AI Roundtable episode, many of the experts believed only a handful of LLMs which are in the market today will still be used in 12 months-time.
This is also the first time where, unlike the past technology waves, Asia is not necessarily playing catch up to the US. Asia has leapfrogged to be in the real position to become as AI-native as the US by participating from the start, mentioned by Sundar Pichai (CEO of Alphabet Inc.) at the APEC CEO Conference.
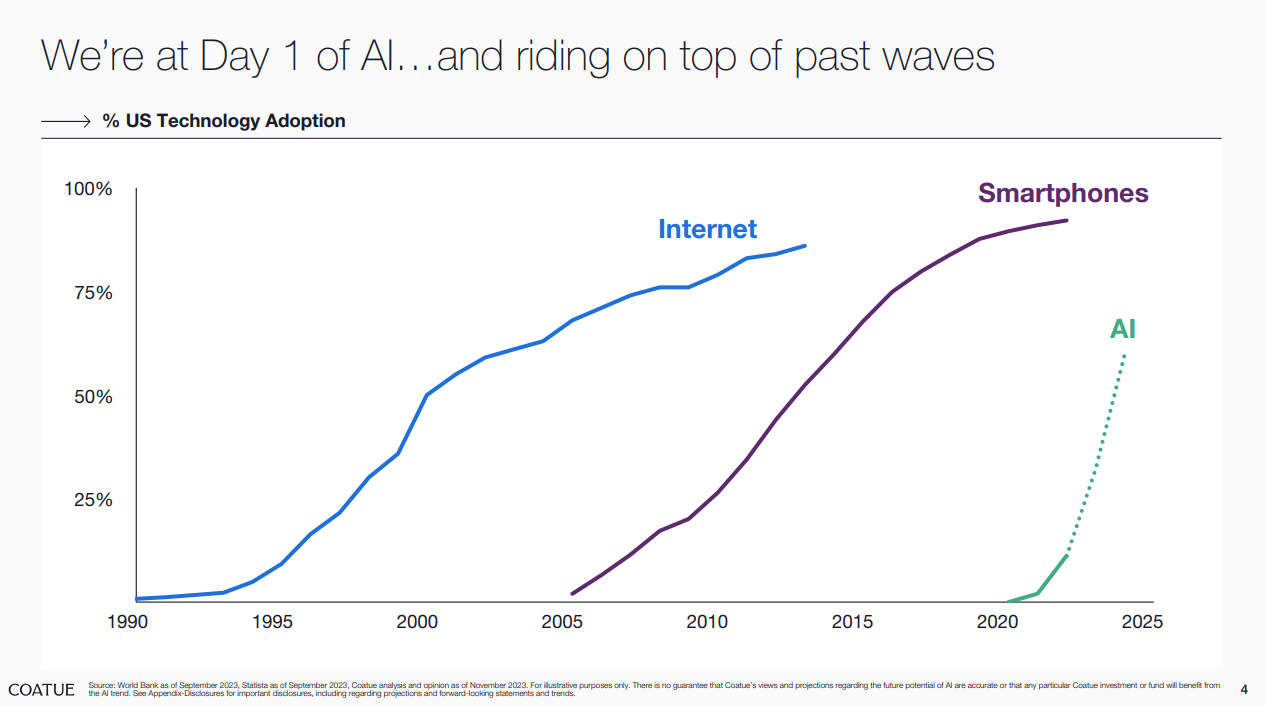
But, how did we get to this point? Is it just a hype or are there any fundamental shifts which allow Generative AI to sustain once the initial hype wears off? This article by CSM Technologies provides a good read on the complete history and evolution of Generative AI. In the most recent context of Generative AI, we believe these are the 4 key catalysts behind Generative AI’s meteoric rise and why it will stay:
Increased computational power: The computational power of GPUs has significantly increased over the past 10 years. For example, NVIDIA GeForce RTX 3090, a high-end GPU released in 2020 with 35.58 teraflops of computing power (based on single-precision floating-point performance) is ~24X more powerful than NVIDIA GeForce GTX 480, which was released in 2010 (1.5 teraflops). Similarly, AMD Radeon RX 6900 XT (released in 2020 with 23.04 teraflops) is ~6X more powerful than AMD Radeon HD 7970 (released in 2011 with 3.79 teraflops). Furthermore, GPU processing efficiency has increased significantly over the past 25 years, as evidenced by NVIDIA and AMD raising their processing performance per unit die density (i.e., physical size) and unit TDP (thermal design power, i.e., power consumption). The growing prominence of cloud computing platforms like AWS, Azure, and GCP is also a meaningful tailwind which plays a role in accelerating this trend.
Growing availability of large datasets: Over the past 10-15 years, the increasing prevalence of digital platforms has led to a significant expansion of digital footprints and therefore digital activity / interaction data. As a result, recent LLMs (Large Language Models) were trained using datasets that are significantly larger than those used in old machine learning models 10 years ago. For instance, the GPT-3 model, released in 2020, was trained on 570GB of text data (with 175B parameters in the final model), while the GPT-2 model, released in 2019, was trained on 40GB of text data (with 1.5B parameters in the final model). These numbers are incomparable to what machine learning models 10 years ago typically used, which were often in the range of a few gigabytes or less.
Advancements in neural network techniques and particularly deep learning: Deep learning is a branch of ML which uses artificial neural networks to mimic the human brain’s learning process. It is characterized by multiple layers of interconnected neurons that hierarchically process data, allowing them to learn increasingly complex data representations. Deep learning algorithms require large amounts of data and can work with unstructured data such as images, text, or sounds. Since neural network was first introduced in 1990s, it has continued to evolve. In 2000s, the underlying groundwork for deep learning and GAN (Generative Adversarial Network) was introduced, enabling the generation of realistic data. In 2010s, GAN’s synthetic data generation capability was expanded to more types of data (i.e., image, video, voice) and the Transformer network architecture was introduced, soon followed by GPT (Generative Pre-trained Transformer).
Development of open-source tools and communities: Open-source tools are software products which are publicly accessible. Anyone can see, modify, and distribute the code as they see fit. Open-source projects such as TensorFlow, PyTorch, and Keras have played a pivotal role in democratizing access to generative AI, enabling a broader community of developers and researchers to explore and innovate in this field. Currently, there are 8,000 open-source Generative AI projects identified in GitHub. These projects range from commercially backed large language models (LLMs) to experimental initiatives, offering numerous benefits to open-source developers and the machine learning community. Although we have seen some decline in initial excitement from AI “tourists” on GitHub (as measured by # of stars given to AI/ML repo as percentage of total new GitHub stars), serious AI builders remain in the platform (as measured by # of AI/ML repository commits as percentage of total commits in GitHub).
With continuous advancement in technology (computational power, large dataset availability, and deep learning techniques) and availability of platforms for the researchers and developers community to keep grinding it out, we believe that the surge of innovation in Generative AI will keep on coming, better and faster.
How do we think about it?
Now comes the fun part - to find where value lies in Generative AI. We will not keep it too rigid but as much as we can we will try to unpack the following 3 questions. 1) How do we break down the Generative AI ecosystem, 2) What is happening in each part of the ecosystem and who are the key players, and 3) Where is the money.
There are many ways we can structure this: by layer, by modality, by vertical, etc. As someone who used to code and study a little bit of data science but no longer have sufficient technical expertise to call myself an engineer or data scientist, we generally think it is easiest to understand when we break it down by layer, so that’s what we will do in this article.
Important note: There are multiple ways to structure Generative AI stack
We will structure the Generative AI stack into 4 layers: Foundation layer, model layer, tooling layer, and application layer. Within each layer, we will look at what are the sub-categories, who are playing in this space (incumbents and new entrants), and what are the recent developments. In this article, we will deep dive on layer 1 and 2, and we will uncover layer 3 and 4 in another article separately.
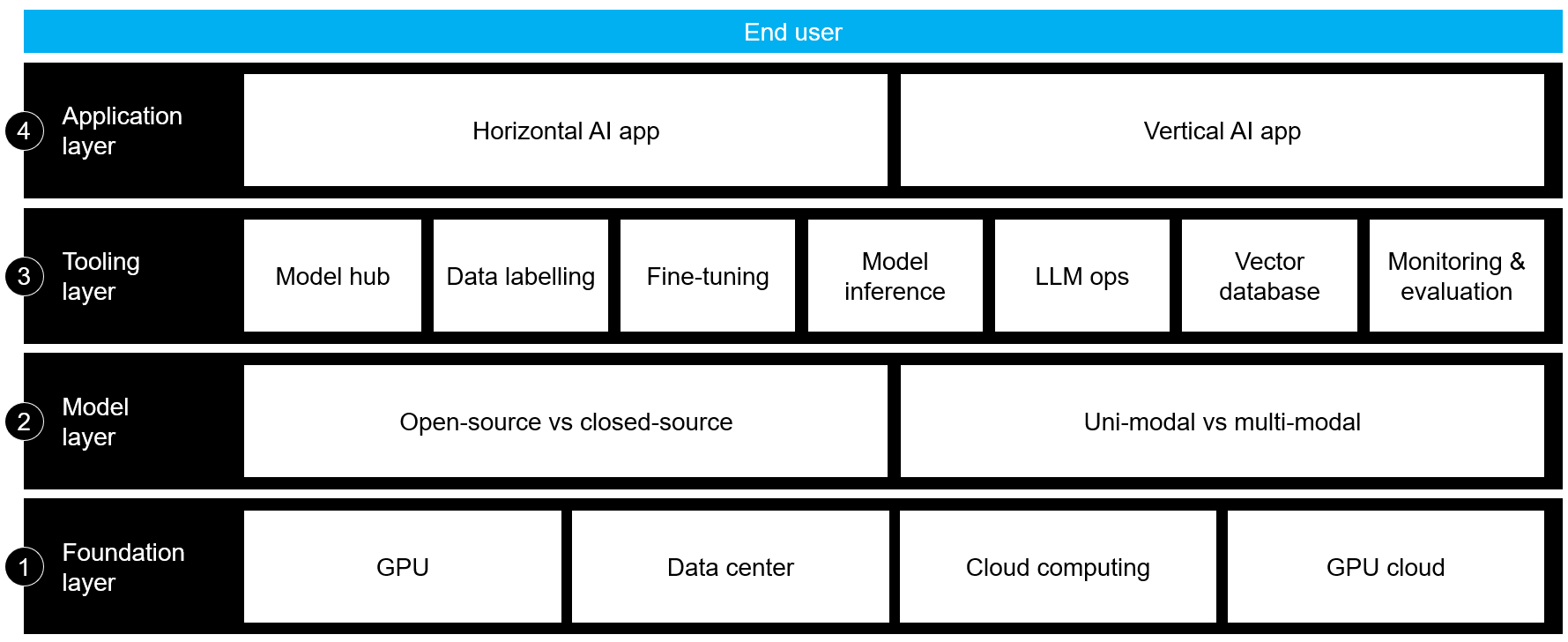
Foundation layer is the base of the stack. It includes infrastructure and resources needed to support Generative AI applications (i.e., computing power, storage capacity). As such, the sub-categories within this layer are the GPU, data center, cloud computing, and GPU cloud.
Model layer consists of the advanced foundational models which are the core engine in every Generative AI application. Foundation models are a class of large-scale, adaptable AI models trained on a broad dataset that can be adapted and fine-tuned for a wide variety of applications and downstream tasks. One way to look at this layer is by the unique features of each foundation model, for example LLM, GAN (Generative Adversarial Network), VAE (Variational Autoencoders), diffusion models on various modality, among others. To fully understand the unique nuances of each type of model, you can look at the technical explanation here. In this article, we will break down this layer in 2 ways: open-source vs closed-source and uni-modal vs multi-modal systems.
Tooling layer is what enables technologies in foundation and model layer to be fully utilized and translated into Generative AI application, in particular for companies who don’t use proprietary foundation model. We can break down this layer into the following sub-categories: model hub, data labelling, training & fine-tuning, model inference, LLM ops, vector database, and monitoring & evaluation.
Application layer is where the diverse use cases of Generative AI come to life, this is the layer where human will interact with AI. Some Generative AI apps use their own proprietary model, so they are integrated with the model layer (e.g., Midjourney, Runway), but majority are built on existing open-source foundation models (e.g., Jasper, Harvey). The sub-categories in this layer are horizontal (functionality-based) app and vertical (industry-based) app.
1. Foundation layer
As we chart the path forward in Generative AI, there are 5 themes in the foundation layer which we expect to define the landscape and will closely follow:
Nvidia is leading the race amongst the major GPU manufacturers, but others such as AMD are expected to follow suit driven by massive Generative AI tailwind which create a prolonged GPU supply shortage.
Major data center operators are making tie-ups with local governments of high-potential emerging markets such as Southeast Asian countries (e.g., Indonesia, Malaysia) to overcome regulatory hurdles (e.g., data localization policies).
Emergence of new entrants in data center space developing novel solution for power efficiency and sustainability, cybersecurity, cooling, or building edge data centers.
Cloud service providers will have dual strategic priorities of improving their legacy businesses to push cloud adoption and building a full suite of AI solutions which include hardware & software stacks.
Emergence of specialty players offering GPU cloud services for AI app companies with flexible pricing scheme targeted for smaller enterprises with limited capital but higher degree of demand uncertainty.
Introduction to foundation layer
The growth of Generative AI is currently not capped by the consumer demand, but by the supply of GPU, which is essential to power the resource-intensive training and inference of large foundation models. Companies have to wait to buy more GPUs as its demand is dwarfing its supply. As a result, unsurprisingly, the prices of GPU has been skyrocketing (the latest Nvidia GPUs could go up to US$ 40,000) and chipmakers are benefiting massively from this tailwind.
Besides chipmakers, data center operators and cloud service providers are also significantly impacted by Generative AI’s rise. Demand for both data center and cloud computing services surged due to increasing requirement for stronger computing power, server density, and cooling capacity to support AI workloads. This comes along with new sets of challenges, such as power efficiency & sustainability or cybersecurity, which incumbents and new entrants are racing to address in order to gain competitive edge.
Another interesting development in this market which we will also discuss in this section is the rise of specialty GPU cloud service providers tailored for AI companies. These players are providing GPU computing capacity for small to mid scale AI companies who do not have the capital and resources to buy and manage their own stack of GPUs. Of course they are competing against incumbent cloud service providers, but given the GPU supply shortage, they have ample room to gain sizable traction within short period of time.
GPU
As the pioneer of full-stack accelerated computing approach, Nvidia has historically been by far the leading player in this space (controlling 80% market share), and we can see how this phenomenon reflects in their numbers. Nvidia’s quarterly revenue grew 3x YoY from US$ 6Bn in Q3 2022 into US$ 18Bn in Q3 2023. Unsurprisingly, the largest driver is data center segment, which contributed to US$ 14.5Bn revenue (almost 80% of Nvidia’s total revenue) in Q3 2023 and grew 3.8x YoY. What’s even more remarkable is their net profit which jumped 13.5x YoY from US$ 680Mn (11% net margin) to US$ 9.2Bn (51% net margin) during the same period.
We expect Nvidia to continue making significant strides to maintain their forefront position in the market. They are launching the H200 GPU, which will start shipping in Q2 2024 and can boost inference speed up to 2X compared to its predecessor (H100 GPU) when handling LLMs such as Llama-2. Furthermore, they are partnering with leading enterprises globally to accelerate go-to-market to key industries & markets and solidify their position early. A few notable examples:
With Foxconn, they are building “AI factories”, a new class of data centers tailored to support wide range of AI applications in manufacturing, e.g., industrial robots, self-driving cars
With Greentech, they are working to accelerate drug discovery process by powering Greentech’s proprietary algorithm on their BioNeMo and Nvidia DGX Cloud
With India tech giants (Tata, Reliance, and Infosys), they are working to accelerate AI in India by bringing state-of-the-art AI infrastructure and building people capabilities on AI
Beyond that, Nvidia are broadening their full stack suite of software and hardware solutions to build and run enterprise Generative AI applications through their AI Foundry services and AI Enterprise ecosystem.
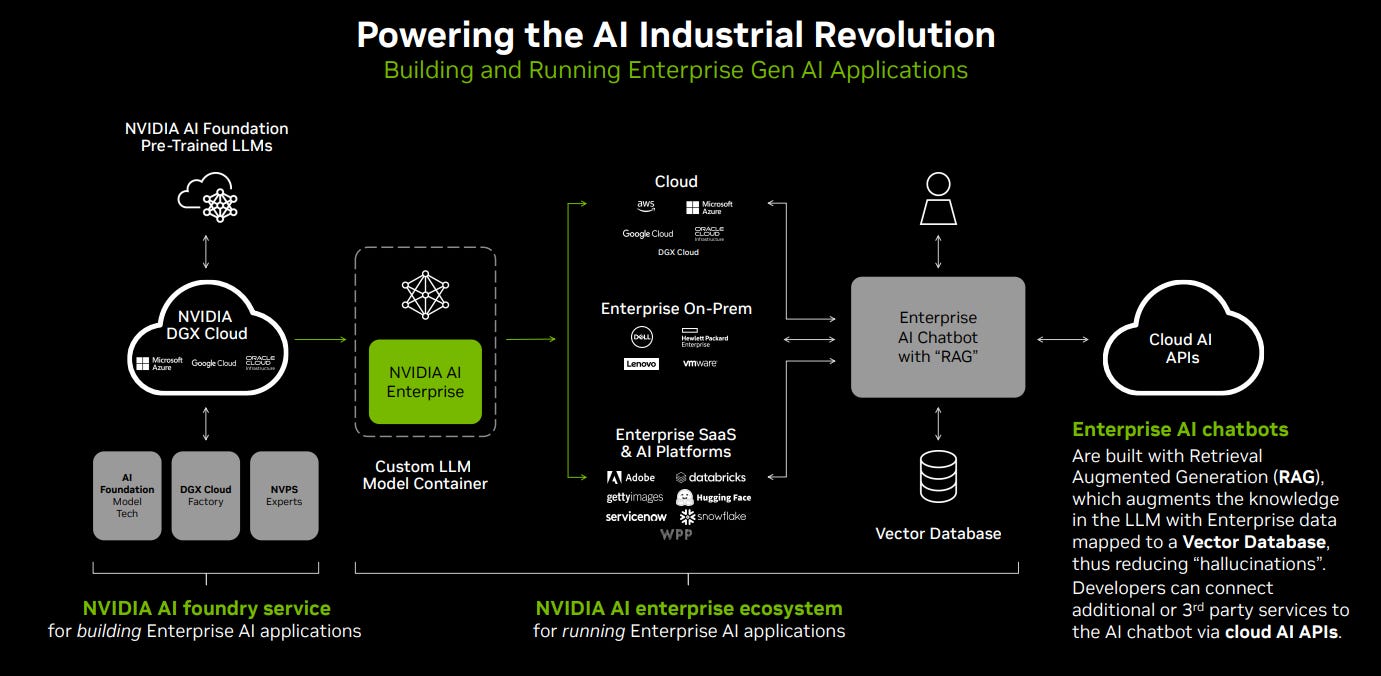
We covered a lot about Nvidia, but they are not the only winner in this market. Given the supply shortage, major enterprises are starting to look for alternatives. One player which is in prime position to capture this opportunity is AMD, who earlier this year announced the launch of their newest Instinct MI300X GPUs, “the highest-performance accelerators in the world for generative AI” as an alternative to Nvidia’s H100 GPUs. Major enterprises such as OpenAI, Microsoft, and Meta are all set to use it starting Q1 next year. OpenAI plans to use MI300 in its Triton 3.0, Meta will use thousands of MI300X in its data centers, while Microsoft will deploy it within their new Azure ND MI300X V5 virtual machines, the cloud hosted servers optimized for AI workloads. Though has not been reflected in their latest P&L, we expect them to have a similar jump with what Nvidia had from 2022 to 2023 in the next 12 months.
Another movement in this space worth noting is how large cloud-computing companies like Google and Amazon have developed custom chips in-house designed for their own data centers, though they are not necessarily moving away from buying traditional chips from the GPU manufacturers. Apple has also done similar thing since it introduced its first in-house built chip (M-series) in 2020. Apple’s in-house chips was a breakthrough which allowed them to improve security and customer experience by deploying AI models at the edge on Apple’s interconnected devices (i.e., iPhone, Apple watch, AirPods, MacBook).
We expect major chipmakers to maintain their market leadership as they race to capitalize the Generative AI opportunity, particularly in 3 aspects: 1) Raw performance and efficiency (in terms of physical space and power consumption), 2) AI ecosystem, including both hardware and software solutions (e.g., tools, libraries, enterprise-grade security solution, and other value add services), and 3) Use of novel technologies to find new angle of differentiation (e.g., edge AI, neuromorphic chips, or AI-driven chip design).
There are opportunities for new entrants to specialize in providing GPU computing solutions for smaller enterprises who are building AI products (i.e., require tremendous computing power) but might not have the capital or resource to buy their own GPUs. We call these players the GPU cloud provider and will delve into it in the next sections.
Data Center
Data centers are generally operated by 3 types of companies:
Large enterprise who build their own enterprise data center network to support their internal IT infrastructure and services. These includes your big tech companies like Google, Meta, or Microsoft, or government agencies with high requirement for control, visibility, and data security. These players would just buy the components directly from the suppliers like Nvidia, AMD, or Intel for GPU, or Hewlett Packard, Dell, or IBM for servers, storage, and networking equipment, then build and operate the data centers themselves.
Cloud service providers who build cloud data center network specifically to serve their customers, for example AWS, Azure, GCP, or Alicloud. In these physical facilities, customers of the cloud service provider can deploy and manage their virtualized or non-virtualized resources without having physical access to the actual facility. Key difference between cloud and enterprise data center is scalability. Enterprise data center is typically not as large as a cloud data center (what people usually refer to as the “hyperscaler”) as their data centers are made to serve their own internal needs only. Meanwhile a hyperscaler is made to provide their cloud services all over the world. Typically, large enterprises who need an additional capacity would connect their enterprise data center with a public cloud data center to add scalability to their on-prem data centers.
Data center operators who mainly build colocation data centers to offer shared infrastructure and resources to multiple users and edge data centers to bring small-latency but high-security data center services closer to the end users. Some of the largest data center operators include Equinix, CoreSite, and Digital Realty. Colocation works in a similar way with cloud data centers, but they key distinction here is how data is managed and stored. In a colocation data center, server is owned and managed by the businesses who are leasing the space, whereas in cloud data center, server is owned by the cloud service providers and data is managed virtually. Major players like Equinix has 250+ data centers and are serving over 4,000 customers worldwide, from large enterprises to early-growth stage tech companies, as 15% of their revenue came from companies with <US$ 50Mn revenue.
Similar with the GPU manufacturer market, we expect these 3 groups of incumbents to maintain their dominant position in the market. That being said, we also see a room for new entrants to play in this space by focusing on specific niche or providing complementary solutions to existing data center operators. Based on a series of interview conducted by Prylada with 24 experts from the data center industry, there are 3 most pressing challenges that leading players are racing to address: 1) power efficiency and sustainability, 2) cybersecurity (and also physical), and 3) environmental issue and cooling.
Companies like Lancium are building large-scaled data centers located in areas with excess renewable generation to address geographical mismatch between where the most wind and solar energy are generated and where they are needed. They also develop proprietary technology ‘Lancium Smart Response’ which allows their customer to nimbly adjust the power grid usage to optimize their clean power usage and provide more flexibility & cost efficiency for their customers.
Cooling is an important aspect to consider for data centers, as it accounts for 40% of a data center’s energy consumption. As demand for computing continues to surge and more powerful chips are being rolled out to the market, power density in the data centers will also increase and there will be more demand for effective & efficient cooling systems. We are seeing emerging companies like JetCool Technologies (est. in US in 2019) or Nostromo Energy (est. in Israel in 2017) specializing on providing cooling solutions for data centers. JetCool Technologies offers direct-to-chip liquid cooling solutions for data centers, while Nostromo Energy builds the “IceBrick” system to store clean energy (solar, wind) and use it to power their 24/7 cooling solution.
Another potential opportunity for startups is edge data center. IDC forecasts enterprise spend in edge computing to grow 10-15% as businesses are becoming more aware of what they should and should not store in the cloud. Generally, edge data centers offers faster response time & lower latency due to the lower distance data has to travel and higher security due to less risk of data interception during transmission. With that, edge data centers will inherently be more suitable for some use cases such as gaming, virtual reality, or autonomous driving. We have seen some emerging players building in this space gaining significant traction and drawing attention from larger players, such as Spectro Cloud (est. in US in 2019) who raised US$ 67.5Mn funding incl. from T-Mobiles and Stripes, Edge Presence (est. in US in 2017) who raised US$ 30Mn and got acquired by Ubiquity, or MobiledgeX (est. in US in 2017) who got acquired by Google.
In Southeast Asia, the data center space is still nascent but has huge potential, with total size of US$ 9.7Bn in 2022 and expected CAGR of 6.6% to reach US$ 14Bn in 2028. Thus far, Singapore accounted for ~55% capacity in Southeast Asia, but we expect other countries such as Indonesia, Vietnam, and Malaysia to also experience significant growth spearheaded by their data localization laws. In Indonesia, the data center capacity is currently around 500MW in 2023 (as comparison, data center capacity in the US is 5GW in 2023) and is expected to grow into 1.4GW by 2029.
We are seeing influx of investments from regional and international players into the Southeast Asian markets, some are done through partnerships with key local stakeholders in response to the data localization regulations. Earlier in September 2023, GDS signed a strategic partnership with INA (Indonesia’s sovereign wealth fund) to build data center ecosystems in the country. Last year, Singapore relaxed their moratorium on new data center development which was signed in 2019 and welcomed Equinix, Microsoft, GDS, and AirTrunk-Bytedance to start pilot projects of 80MW data centers in the country.
Cloud computing
Enterprise spending on cloud computing has been growing 22% per year in the past 5 years. The rise of Generative AI will only help to accelerate this growth even more. On one hand, massive computing resources required to support Generative AI applications will deliver a demand boost for them. On the other hand, cloud service providers must also be aware that there are still a great deal of companies playing catch up to the legacy cloud services and are years away from thinking about what to do with Generative AI.
Major players in this space have started investing heavily in Generative AI related services and tools with aim to differentiate themselves as the go-to-platform for next-gen AI enterprises. AWS, GCP, and Azure are all expanding vertically in the AI layers by embedding various AI tools (e.g., vector db, model deployment tool, fine-tuning tool), foundation models, and model hub as part of their cloud computing solution. They even develop their own custom GPUs for their data centers due to supply shortage of traditional GPUs (as elaborated in previous chapter). This chart from The New Stack provides a good depiction of the AI race amongst cloud service providers.
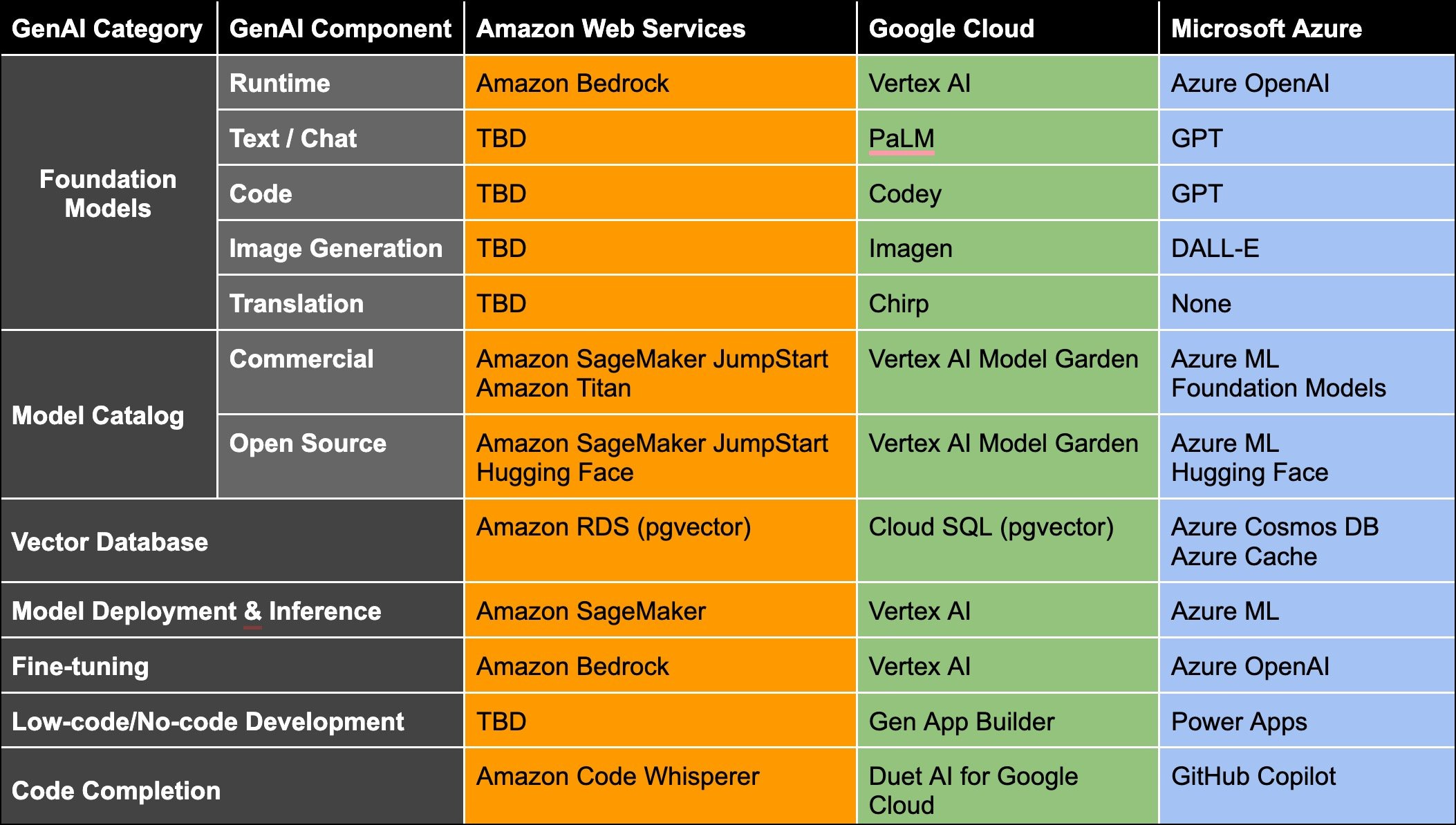
However, as mentioned above, cloud adoption is overall still in its early days. In 2023, worldwide cloud revenue is still ~20% lower than traditional/on-prem. Of course we do expect cloud to eclipse on-prem services in the next 1-2 years, but for now even some of the largest enterprises are still in the process of migrating their systems to the cloud, and they are not moving very swiftly either. Their immediate priorities are simply to ensure that their systems are stable, secure, and performing appropriately. Given the limited tech resources, putting Generative AI as a priority will inevitably affect the capacity of cloud service providers for running and improving their legacy cloud services.
There are still a lot to do on their legacy business, such as improving storage capacity, providing more support to smoothen transition from on prem to cloud infrastructure, ensuring operational stability once clients are onboarded to the cloud (i.e., system stability, system security, data security, system performance). Though it seems like a hygiene, legacy cloud services are consistently experiencing incremental improvements, which incumbents will not be able to keep up with if they are about to enter an auto pilot mode to run this business.
Furthermore, we are seeing a lot of emerging Generative AI native challengers who are offering tailored cloud computing services for AI applications as well as AI tooling solutions (e.g., vector database, fine-tuning, model inference, LLM ops, monitoring & evaluation, model hub/catalog, data labelling). Given the dynamism and ever-evolving nature of the Generative AI space, incumbents willl certainly need to invest significant amount of tech resources for R&D and execution to keep their AI solutions competitive in the market. This is a good segway to the next part of this layer, which is the GPU cloud providers.
GPU cloud
As briefly mentioned in the previous sections, companies of different sizes are exploring how they can leverage AI to enrich their offerings. But a lot of these companies do not have the capital and resources to buy and manage their own stack of GPUs, and even if they have the capital, many are still at exploration or pilot stage, where the demand for GPU computing capacity is not yet reaching a scale and consistency level which makes sense economically to purchase their own GPUs. As a benchmark, companies like Inflection, who is building a personalized AI assistant ‘Pi’ to compete against ChatGPT, is operationalizing a cluster of 22,000 Nvidia H100 GPUs to support their training and inference needs. If we take an average price of US$ 30,000 for each Nvidia H100 GPU, it means Inflection invested over US$ 660Mn to build this infrastructure alone, which is not an amount that a lot of companies can afford.
With that context, there are 3 types of GPU cloud providers based on level of control & flexibility offered for the customers: serverless, virtual machine, and bare metal.
Serverless GPU providers are offering platform-as-a-service (PaaS) solution in which the cloud provider dynamically manages the allocation of machine resources. In a serverless environment, the cloud provider fully manages the infrastructure required to run the code, essentially providing a platform for developers to focus on writing and deploying code without having to manage the underlying infrastructure.
Virtual machine GPU providers are offering infrastructure-as-a-service (IaaS) solution by partitioning a physical server into multiple virtual servers and offering each virtual server instance to a customer. In this scheme, the cloud provider manages the hardware components, but customer has control over the server resources, including the operating system, application, and security.
Bare metal GPU providers are offering exclusive access to an entire server to the customer, so they have complete control over the server's resources and can specify the hardware components for their specific requirements. Bare metal servers are typically used by businesses that require high performance and high degree of control over the underlying hardware, but want to run their own applications and services on the cloud.

As GPU virtualization capabilities become more mainstream, we are seeing newer players expanding their offerings from the bare metal to virtual machine and serverless model, as it is more cost efficienct for smaller enterprise segments. We are seeing new entrants tapping into this space by serving companies who are building AI applications. Many of the players mentioned above (e.g., Modal, Baseten, Jarvislabs) are established only 4 years ago or more recently. Some early players have raised significant amount of funding, such as CoreWeave (est. in US in 2017) raising more than US$ 3.5Bn in debt & equity and was most recently valued at over US$ 7Bn, or Lambda Labs (est. in US in 2012) raising over US$ 110Mn.
In terms of pricing, big tech players generally charge a premium for the same GPU cloud due to brand reputation, proven reliability, and seamless integration with their other services (e.g., AWS with their AWS SageMaker, Amazon S3, Amazon RDS, and other storage services). However, in reality the price might not be as jarring as large enterprises would typically negotiate price when using big tech GPU clouds at a large scale (and extended time period commitment) and specialty players like Coreweave or Lambda Labs can offer aggressive pricing to smaller companies.
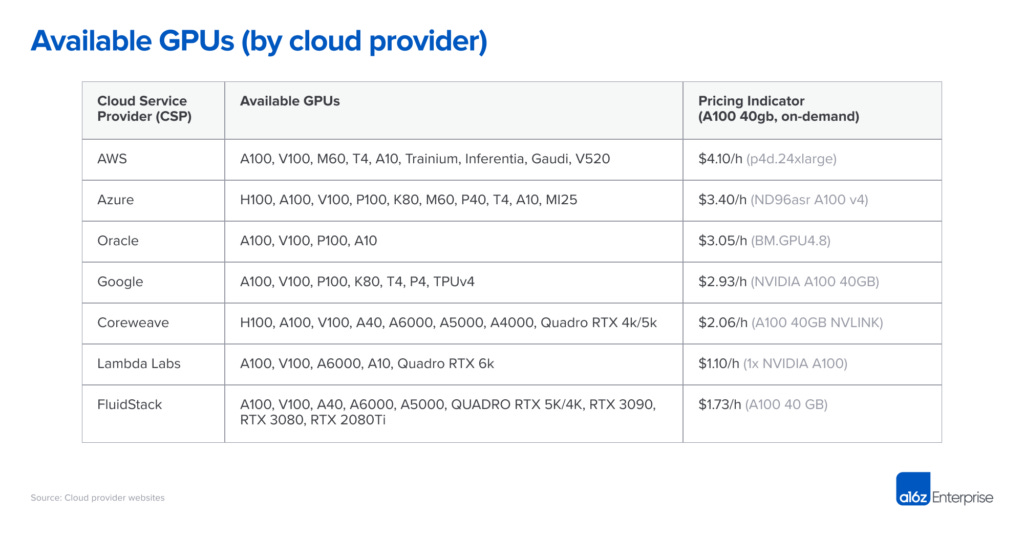
As of now, the most important thing for a GPU cloud provider is availability. As long as they are able to get a substantial supply of GPU from the chipmakers, even a completely new entrant could have an ample room for growth at a healthy margin. We might see some interesting development in this space based on the GPU supply-demand balance in the coming years.
It is entirely possible that the GPU shortage will not be fully resolved in the next 3-5 years as growth of demand will continue and it takes time for chipmakers to massively increase their capacity. Furthermore, it is also in the best of interest of chipmakers to have some degree of scarcity in the market. Consequently, we think that major GPU cloud players will start building their own specialty chips to better serve their niche. In fact, as discussed in the previous sections, big tech players have started developing their own chips in recent years, and we might see specialty players follow a similar route. Besides that, we could also see more M&A activities by the major players in the near future to acquire larger supply of GPUs and customer base at speed.
In the event that GPU supply shortage is resolved in the near future, specialty players will face a pressure to more radically differentiate their IaaS/PaaS/bare metal solutions. As an example, Coreweave has an interesting concept where it enables users to rent out their idle GPUs, essentially becoming a peer-to-peer platform. But time will tell where the market heads and we should look closely on the supply-demand development of GPU and as a key leading indicator for this market.
2. Model layer
As we chart the path forward in Generative AI, there are 4 themes in the model layer which we expect to define the landscape and will closely follow:
Continued race amongst leading players to invent new approaches to improve model performance without proportionally increasing training cost, such as RL-AIF (Reinforced Learning with AI Feedback) used by Anthropic, SMoE (Small Mixture of Experts) used by Mistral.
Emergence of locally-oriented LLMs to address unique context, nuance, and requirements of different regions, such as Sarvam AI or Wiz AI. Monetization and scalability will be a key open question which these players need to address.
Hybrid approach between open-source and closed-source adopted by leading companies as regulatory landscape matures and more advanced safeguard measures are invented.
Evolution of multi-modal systems, where any-to-any Large Multi-modal Models (LMM) becomes mainstream at commercial scale and AI assistants are able to not only process multi-modal input but also generate multi-modal output.
Introduction to foundation model
Foundation model is the DNA which gave birth to Generative AI, itrepresents a new paradigm in AI development as they are designed to be flexible and adaptable, in contrast to traditional AI’s task-specific nature. The term “foundation model” itself was coined by The Stanford Institute for Human-Centered Artificial Intelligence's (HAI) Center for Research on Foundation Models (CRFM), defined as “any model that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks”. By this definition, foundation model could be uni-modal (focus on single type of data type, such as text, image, audio) or multi-modal (capable of processing and generating content across multiple data types). In the following parts of this article, we will discuss about both uni-modal systems (particularly its recent development and open-source vs closed-source consideration) and multi-modal systems (particularly its recent development and future outlook).
Recent development of LLM
Over the past 4 years, there has been a remarkable proliferation of foundation models, which have grown exponentially in size (along with their training cost). GPT-2 (released in early 2019) had 1.5 billion parameters, whereas PaLM (launched by Google in 2022) had 540 billion parameters, 360x more than GPT-2. GPT-4, which is the newest iteration of GPT models launched by OpenAI in early 2023 (not captured on the chart below), had a 1.76 trillion parameters, which is 1000x more than GPT-2. As of now, GPT-4 is still the best-in-class according to most performance benchmarks (e.g., MMLU, ELO, among others), but it won’t be surprising to see another equally (or more) powerful alternative emerge within a few months time and make GPT-4 look obsolete.
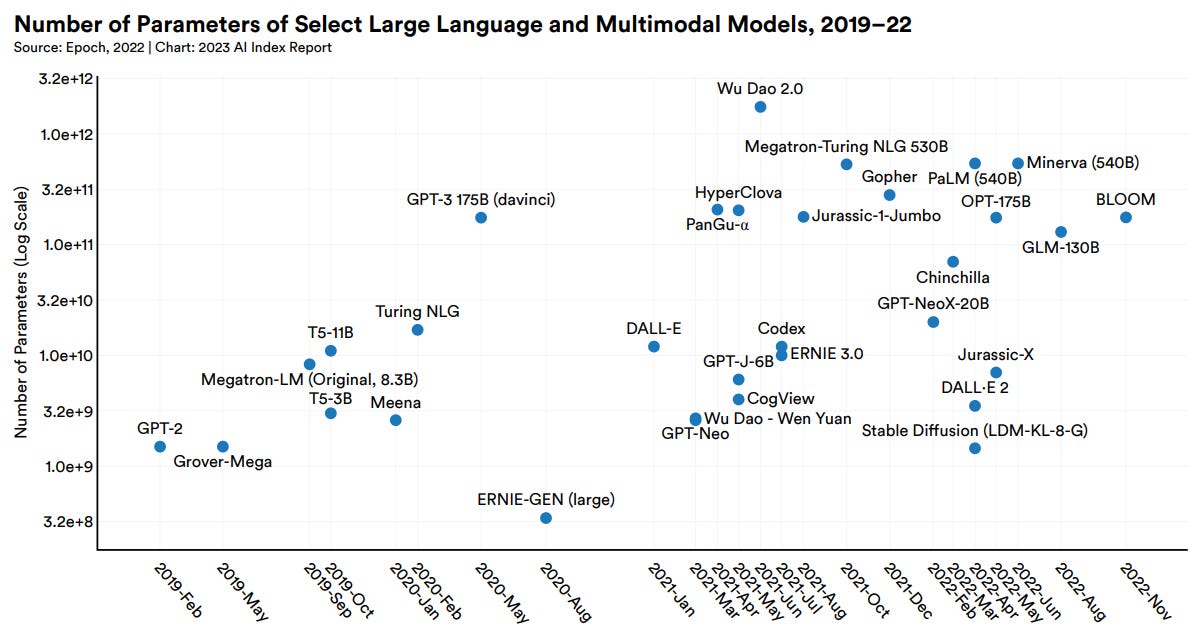
For example, Inflection raised US$ 1.5Bn in the last 18 months focus on building the best personalized AI assistant. Only within 6-months since its inception, its latest iteration of Inflection-2 model was able to achieve near parity with PaLM 2, though still trailing in most benchmark test results compared to GPT-4. They are also supported by strategic investors such as Microsoft and Nvidia, and they have been working to operationalize a gigantic cluster of 22,000 Nvidia’s H100 GPUs to turbocharge its computing power. With this, we can expect them to move swiftly and launch more powerful models to improve their flagship conversational AI chatbot, Pi, in the coming months.
Anthropic is another player in prime position to challenge GPT-4’s dominance. They are pushing the ‘scalable supervision’ narrative to ensure AI models can be both helpful and harmless as they continue to perform more complex tasks beyond human level. On December 2022, they published the white-paper outlining their ‘Constitutional AI’ approach, which basically works in similar way with RLHF (Reinforced-Learning with Human Feedback), but relies on AI-generated feedback instead of human feedback to make it more efficient and scalable. For context, RLHF is a method to ‘safeguard’ a model output by using human-generated label as a guide to sharpen reinforcement learning process. Training a model using RLHF approach would typically require tens-of-thousands of human-generated label, whereas Anthropic’s Constitutional AI approach would dramatically reduce human input to only 10-100 simple principles written in natural language. Their most recent model, Claude 2.1 was released around a month ago with an industry-leading 200K token context window (vs GPT-4’s 128K), better accuracy, built-in API to access 3rd party tools, system prompts, while offering 20% lower cost vs GPT-4 (US$ 0.008 per 1K token of Claude 2.1 vs US$ 0.01 per 1K token of GPT-4).
Developing larger foundation models also comes with a massive training cost. Training cost of GPT-2 was around US$ 50K, meanwhile training cost of GPT-4 was around US$ 100Mn (2000x more expensive). We are seeing new AI companies raising massive funding rounds even before they launch their first product, e.g., Anthropic raised US$ 7.6Bn, Inflection raised US$ 1.5Bn, Mistral raised US$ 660Mn, Character.ai raised US$ 150Mn, among others. Most of these companies were founded by ‘AI mafia’ (who previously were senior executives at Google DeepMind, OpenAI, or Facebook Artificial Intelligence) who are trying to address issues / flaws unsolved by existing incumbents.
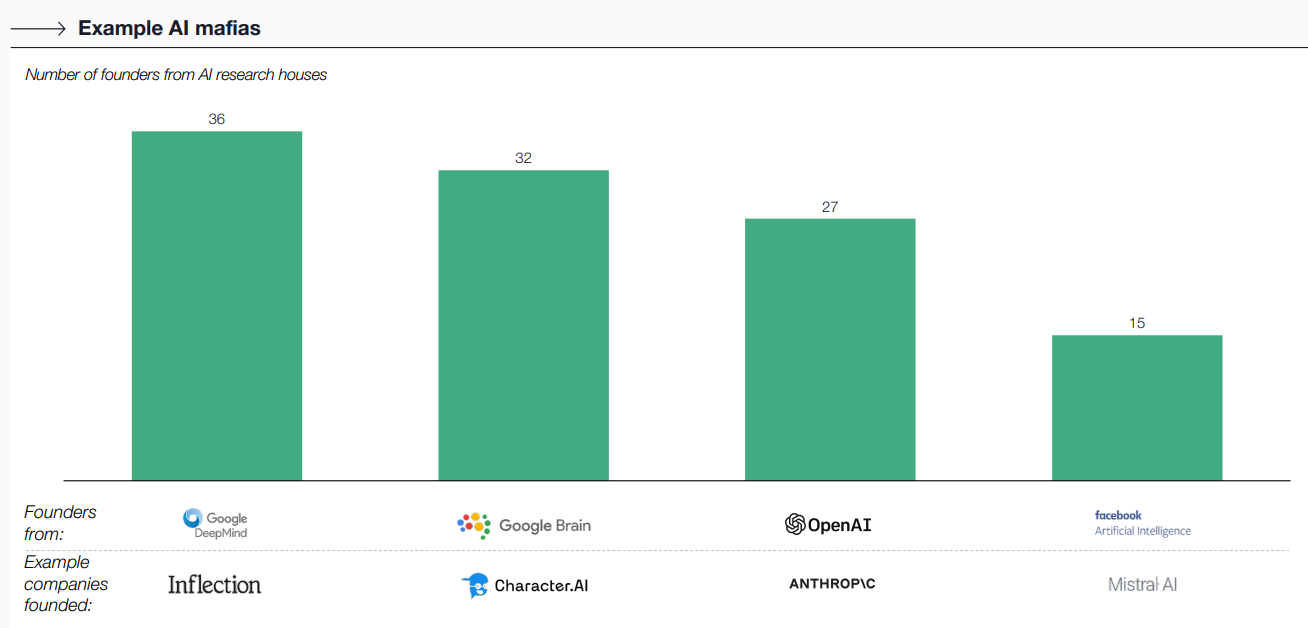
To work around the massive training cost, leading players are also racing to improve foundation model’s efficiency. For instance, Mistral recently launched the Mixtral 8x7B which was built using the SMoE (Small Mixture of Experts) architecture, which basically allows the model to direct specific inputs to designated ‘experts’ within its vast network so it can efficiently scale without proportionally increasing computational resources. With this SMoE architecture, Mixtral 8x7B has ~47B parameter, but only uses ~13B parameter per token therefore it is able to perform like a 47B parameter model with the efficiency of a model with 13B parameter. As a result, Mixtral 8x7B was able to match or outperform Llama-2 70B on all performance benchmark and handle multiple languages (English, Germany, French, Italian, and Spanish), while being 6x faster in inference.
Besides improvement in performance and efficiency, we are also seeing new players developing locally-oriented LLMs trained on local language-based token to address unique context and requirement in each region. For example, Sarvam AI developed OpenHathi - the first LLM which can talk in Hindi, Wiz AI developed Wiz LLM - the first LLM built in Southeast Asia, which specialize in Bahasa Indonesia. They are also planning to expand Wiz LLM capability to other languages in the region such as Thai. We see the merit of having a localized LLM as it helps to democratize AI use cases in developing economies where English is not a common language especially amongst the mass segment, for example customer service, telesales, among others. The open question with this localized model is market size. In India, the market might be large enough for a player to specialize in developing a locally-oriented full-stack Generative AI solution. However, in Southeast Asia, one market might not be sizable enough, hence locally-oriented players will need to find the right monetization model to ensure their potential upside is worth the effort required to tailor their LLMs to each local market (i.e., Indonesia, Thailand, Vietnam, etc.).
Open-source vs closed-source
Foundation model can be made open-source or closed-source and there has been many arguments brought up by experts on this topic which encompass commercial consideration, ethic and safety consideration, among others. To give an initial picture, some open-source examples include Mistral’s Mixtral 8x7B, OpenAI’s GPT-2, or Stability’s Stable Diffusion XL, and some closed-source examples include OpenAI’s GPT-4, Anthropic’s Claude 2.1, or Inflection’s Pi.
If we look back into the previous tech waves, as a16z highlighted in one of their recent blogs, a lot of systems which power modern computing are currently open-source: server operating systems (Linux), virtualization (KVM, Docker), databases (Postgres), data analytics (Spark, DBT), programming languages (Javascript, Python, C), web servers (NGINX). The main reason is because giving access to the broader community could accelerate the positive flywheel of identifying & fixing bugs, innovating features, and strengthening security.
A few investors, in a recent interview with TechCrunch, also echoed the benefit of open-sourcing foundation models and highlighted that open-source models are more explainable as they can be inspected by anyone, hence easier for them to obtain trust from boards and executives. However, they also acknowledged that open-source model does carry meaningful risks without proper fine-tuning and safeguard measures.
Generally, there are 2 big consideration against open-sourcing a foundation model:
Commercial: As discussed above, the space is extremely dynamic and there are many 1-2 years old players who have built LLMs which can challenge incumbents in terms of both performance or efficiency. OpenAI’s Co-Founder and former Chief Scientist, Ilya Sutskever, acknowledged that as of now the decision to make GPT-4 closed-source is predominantly driven by the competitive dynamics between the leading players, as the current capability of Generative AI is not yet at the level where it would drive the decision to make a model closed-source.
Security: AI capabilities will continuously increase and eventually it will reach a point where it might be dangerous to open source everything, as it will be more prone to people exploiting the code, especially for certain use cases which are sensitive by nature, for example biotechnology/genetic, healthcare, social and politics. We also saw how Generative AI models was used to spread misinformation or inappropriate content by irresponsible users, so it is essential to carefully consider the ethical and security implications before open sourcing AI technologies.
Going forward, we expect the industry to adopt a more hybrid approach which strike a balance between open-source and closed-source. There are 3 things we believe:
Both open-source and closed-source are here to stay. Developer community is the backbone of every tech wave and open-source models accelerate AI innovation and adoption. That being said, there are also merit in closed-sourcing a model, for example models which are trained and fine-tuned using proprietary data owned by each company. Therefore, we might see companies open-sourcing their base model to crowdsource ideas and inputs from developer communities, but keeping another set of models closed-source to maintain competitive edge.
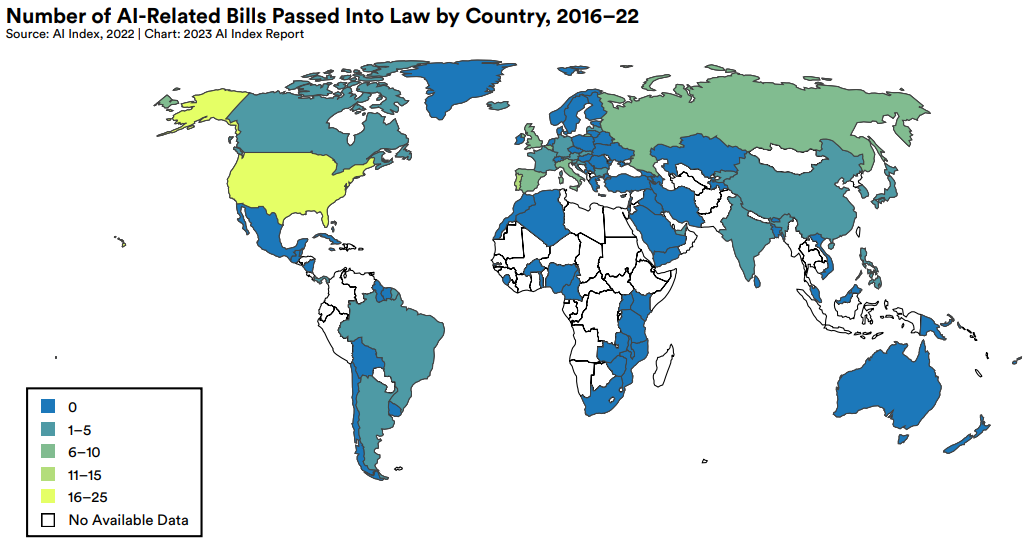
AI regulatory guidelines will become more robust. Since 2016, there have been 123 AI-related legislation bills passed in 127 countries which were included in Stanford HAI’s AI Index Report. This number is also on an uptrend (37 bills in 2022 vs 1 bill in 2016) and we expect this uptrend in number of AI-related legislation bills to continue in the coming years, given the nascency of AI policymaking outside of the US and Europe. As of now, some of the legislation bills, even in the US or Europe, are still quite normative and only addressing general issues. But eventually, we believe there will be increasingly more policies which specifically govern the use and accessibility of Generative AI models related to sensitive topics.

Built-in safeguard measures will become the norm. We are already seeing various approaches introduced by leading players or research communities to minimize/eliminate harm potential of generative AI, such as the RLHF approach or Anthropic’s Constitutional AI approach. As the ecosystem matures , implementing a safeguard measures will become an imperative for every company who want to deploy their Generative AI model to the market.
Uni-modal vs multi-modal foundation model
We have unpacked a lot about LLM as the most popular uni-modal type of model in the previous part of the article. But as mentioned earlier, foundation model is not only limited to text-based model. For simplicity, we will use the term LMM (Large Multi-modal Model) to describe non-text-based foundation model. The case for LMM is quite straightforward:
Training a foundation model require tremendous amount of quality data. However, high-quality text data will eventually be exhausted way before image, audio, or video.
More use cases for foundation models which can generate multi-modal output. Some industries, in particular, would rely heavily on multi-modal capabilities more than others, such as healthcare, robotics, gaming, retail.
Hence, expanding into multi-modality is one of the avenues to improve model performance and expand market size. In terms of improving model performance, the big component of LMM is the ability to embed different modalities into a common multi-modal embedding space, or in simple terms to have a common machine language which can identify and read text, image, or other type of information. Similar to LLM, OpenAI is also a pioneer in this space as it introduced CLIP (Contrastive Language-Image Pre-training) in 2021. CLIP has an encoder which can map data of different modalities (i.e., text and images) into a shared embedding spaceto make text-to-image and image-to-text tasks so much easier.
Since CLIP, newer and more sophisticated LMMs have emerged, and a lot of them are leveraging similar concept as the backbone of their architecture. As of now, there are 2 levels of LMMs based on their complexity and capability:
Input and output are uni-modal but different modalities. Models in this category are mostly text-to-image models, which are able to process text input and generate image output, but they can’t generate text output, for example Midjourney, Stable Diffusion, and DALL-E.
Input and output are multi-modal (any-to-any LMM). Most multi-modal systems today work with text and images and they are limited to input-side multi-modal understanding, but we have started seeing some exciting strides in output-side multi-modal generation recently. This capability is a critical component to develop a human-level AI as humans interact and communicate through various modalities. An example of this any-to-any LMM is NExT-GPT, which was introduced by a group of researchers from National University of Singapore (NUS) in September 2023. This LMM was built by connecting LLM with multi-modal encoder and decoder through an input & output projection layer. They are also built using open-source resources, such as the Vicuna 7B as their LLM, ImageBind as their multi-modal encoder, and various diffusion models for different modal generation, incl. Stable Diffusion for image generation, AudioLDM for audio generation, and Zeroscope for video generation.

For now, we are still at early stage of multi-modal systems, but we are certain that LMMs will be a game-changing capability, even more so than LLMs. We also believe that advancement of multi-modal systems will need to go hand-in-hand with uni-modal systems, as the performance of LMMs is also determined by the performance of its base LLMs, encoders, and decoders.
As we have seen, the Generative AI space is ever-evolving and new entrants, with the right founding team and resources, are able to blitzscale and catch up to incumbents in no time (e.g., Inflection, Anthropic). With the availability of open source resources today, it won’t be a surprise to see a new entrant making massive strides and building the first end-to-end multi-modal systems at commercial scale.
That being said, we would be surprised if incumbents like Apple are not already working on multi-modal systems, especially given how much emphasis they are putting on spatial computing technology. Apple’s soon-to-be-released Vision Pro is the first spatial computer that can blend digital content with physical world. Imagine you can look at your living room and ask your AI assistant to generate different interior design options delivered through Vision Pro interface, then you can zoom-in on each furniture in the interior design to look at its details, price, where to get, etc. This is just an illustrative example, but the potential Apple can unlock by combining spatial computing technology with multi-modal systems will be tremendous and we are looking forward with excitement to see how this space develops in the coming months and years.
Next: Tool layer and application layer
When we started writing this, we started my research from the 4th layer (application layer) because we thought that was the most exciting part, where AI interacts with consumers or enterprise clients and there are seemingly a lot more room for creativity and exploration. But, as I dive deeper, I realized the importance of the other layers. It is impossible to fully understand Generative AI and the tremendous opportunities & challenges that it poses without looking at what lies beneath the surface. That’s why, I decided to put off the upper layer to the next article and focus on the foundation and model layer in this first part.
By any means we are both not AI experts, writing this article was a very enriching process for and we learned a lot along the way. So if you managed to reach here, thank you and we hope you find this article helpful. We are extremely pumped to finish the next one, wishing a great year-end holiday and a greater 2024 ahead for all of us!
Sources:
20VC The Ultimate AI Roundtable podcast
Brief History in Time: Decoding the Evolution of Generative AI by CSM Technology
CNBC article on Meta & Microsoft’s plan to buy AMD GPU in Q1 2024
Stanford University Human-centered Artificial Intelligence AI Index Report 2023
Company presentations of Nvidia, AMD, Equinix
Apple Vision Pro and spatial computing technology introduction